The Riverscapes Consortium organizes and serves data via a data warehouse  . The data warehouse provides access to both the underlying data (packaged in riverscapes projects) as well as making these data explorable via a warehouse explorer or interactive web maps. We only serve and host data packaged in fully Riverscapes-Compliant
. The data warehouse provides access to both the underlying data (packaged in riverscapes projects) as well as making these data explorable via a warehouse explorer or interactive web maps. We only serve and host data packaged in fully Riverscapes-Compliant  Riverscapes Projects
Riverscapes Projects  .
.
GOAL

Make it easier to catalog, share, discover and retrieve the products of riverscapes analysis and modelling.
 Get Data Now
Get Data NowAdvantages
 The advantages of riverscapes projects being hosted in a data warehouse can include:
The advantages of riverscapes projects being hosted in a data warehouse can include:
- Searchable and queryable Warehouse Explorer Catalog
- Custom Web-Maps
- Custom field and desktop Apps

- Secure cloud hosting (typically in
 S3) with:
S3) with:
- Easy public sharing
- Full user access permission control
- Full integration with EC2 and Lambda for cloud-computing of Production-Grade Riverscapes Models.
- Creative Commons licensing of datasets
- Ability to mint DOIs
 to make datasets citable
to make datasets citable - OGC API access to riverscapes projects and warehouse for programmers

- OGC Web Map Tile Services access to your datasets
- Searchable and discoverable in RAVE GIS Toolbars
Overview
In this 8 minute video, we show off what these warehouses buy you in terms of housekeeping and reaching broader audiences.
Riverscape Warehouse Concepts
Warehouse Explorer Concept

Part of the advantage of serving and hosting data in the Riverscapes Warehouse is the ability to catalog and index the data so it easily searchable, queried and discoverable.
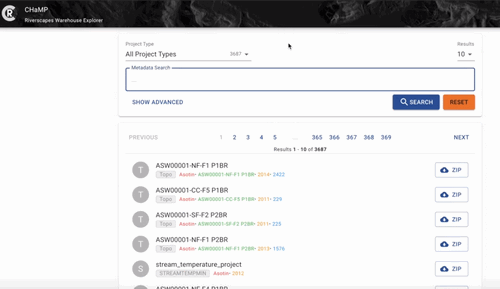
Eample view of a fully searchable and querable data warehouse.
CHaMP Example
When the Columbia Habitat Monitoring Program (CHaMP) was operational, the program produced an immense amount of raw monitoring data, derivative products, model analysis products, and various outputs. For example, from 2011 to 2017, over 958 sites were monitored for fish habitat producing (ISEMP/CHAMP, 2018)., CHaMP crews conducted over 5000 visits to over 950 sites producing a mountain of monitoring data. All of the visit and topographic data was made available in champmonitoring.org. However, the program produced a much richer range of reach scale, network scale and population scale analysis and synthesis products, which cm.org was not designed to accommodate. To test the utility of the Riverscapes Warehouse context, we created a warehouse explorer for the CHaMP Riverscapes Warehouse. Some of its utility is illustrated in the video below.
- ISEMP/CHAMP. (2018) Integrated Status and Effectiveness Monitoring Program (BPA Project 2003-017-00) and Columbia Habitat Monitoring Program (BPA Project 2011-006-00) . Final Technical Report for Bonneville Power Administration. 1280 pages.
Fully-Customizable
Any group or organization can develop their own custom Program in the Riverscapes Data Warehouse, and control how and where it is hosted, who can access it, who has what permissions, etc.
Web-Maps
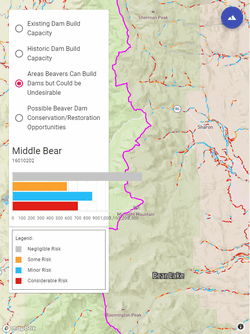
One of the real values in hosting your Riverscapes Projects in a Riverscapes Warehouse , is that web-maps can be produced that allow non-GIS users and non-modelers to interact with riverscape project outputs and explore them. This is an excellent platform to make the outputs of Riverscapes Tools accessible to managers and practitioners to inform riverscape management.
2021 January Update : BLM Montana/Dakotas is currently funding the development of this Web-RAVE functionality by extending the Riverscapes Analysis Visualization Explorer - RAVE. Any project in the warehouse will be visible in an interactive webmap.
Example of BRAT
![]() The Beaver Restoration Assessment Tool is one of the RC’s more mature network model tools. Thanks to BRAT being refactored to produce Riverscapes Projects , and being hosted in a Riverscapes Warehouse , we can produce interactive web maps.
The Beaver Restoration Assessment Tool is one of the RC’s more mature network model tools. Thanks to BRAT being refactored to produce Riverscapes Projects , and being hosted in a Riverscapes Warehouse , we can produce interactive web maps.
While many platforms exist to publish GIS data and share it (e.g ArcGIS Online), they lack the ablity to do so while maintaing the integrity and context of a Riverscapes Project. For example, in one of the old BRAT projects for the state of Utah the data can be downloaded from Utah AGRC, Databasin interactive webmap, or directly from ETAL Box File Server. Only the Databasin interactive webmap download provided a web map, and without any of the context of the rich projects. When users download all the files off our ETAL Box File Server, the need to know a lot about how the model works and how the outputs were produced to find the right context data.
Apps - PWAs
 The future of App develpoment to work across platforms (i.e. iOS, Android, Windows, Linux, etc.) is in progressive web-apps (PWAs) . Another advantage of hosting your Riverscapes Projects in a Riverscapes Warehouse , is that PWA(s) can be developed and deployed to make field or desktop interactive apps to allow users to collect data, do analysis and have it direclty interact with and even update a Riverscapes Project.
The future of App develpoment to work across platforms (i.e. iOS, Android, Windows, Linux, etc.) is in progressive web-apps (PWAs) . Another advantage of hosting your Riverscapes Projects in a Riverscapes Warehouse , is that PWA(s) can be developed and deployed to make field or desktop interactive apps to allow users to collect data, do analysis and have it direclty interact with and even update a Riverscapes Project.
Example of Low-Tech Process-Based Restoration PWA
 The practice of Low-Tech Process-Based Restoration of Riverscapes is something that many members of the Riverscapes Consortium have been working on over the past decade. While a recent manual helped define a standard of practice for design, tracking that information centrally in a design app (a PWA), and having those designs and subsequent monitoring be stored in Riverscapes Projects would allow:
The practice of Low-Tech Process-Based Restoration of Riverscapes is something that many members of the Riverscapes Consortium have been working on over the past decade. While a recent manual helped define a standard of practice for design, tracking that information centrally in a design app (a PWA), and having those designs and subsequent monitoring be stored in Riverscapes Projects would allow:
- The designs conducted in the field, to become immediately useful for GIS analyses back at the desktop.
- Allow holding and submitting designs to central riverscapes warehouses
- Facilitate easier and more transparent action-effectiveness monitoring in the context of those designs.
In the video below Philip Bailey of North Arrow Research illustrates how such a PWA can work (don’t get too excited, its a western town movie set, it is not actually fully plumbed yet ~ i.e. its a proof of concept level of development):
Dataset Discrimination
We refer to ‘datasets’ as any input(s), output(s) or intermediate(s) used or produced by our various analyses, tools and workflows within the Riverscapes Consortium. Within the warehouse, we assign to each “dataset” node or instance within a Riverscapes Project we use a couple of concepts to differentiate and contextualize that data :
- Dataset Grade - Describes the rank of dataset curation using an adaptation of Bloom’s Taxonomy of Educational Objectives
- Data Product Status Tags - Tracks overall status, degree of quality assurance and control, and data generation methods.
As scientists and analysts, we produce a plethora of datasets, some of which go no further than an exploratory analysis and some which are carefully documented, vetted, and validated before being made for external consumption. Not all datasets will proceed sequentially through all stages of dataset status below and some stages are reiterated (e.g. after expert calibration, an output may be requeued for QA/QC assurance. The idea behind dataset discrimination is to keep track of how far, and for what purpose a dataset was
In this 8 minute video, we lay out some concepts we’re exploring with respect to dataset status:
Dataset Rank
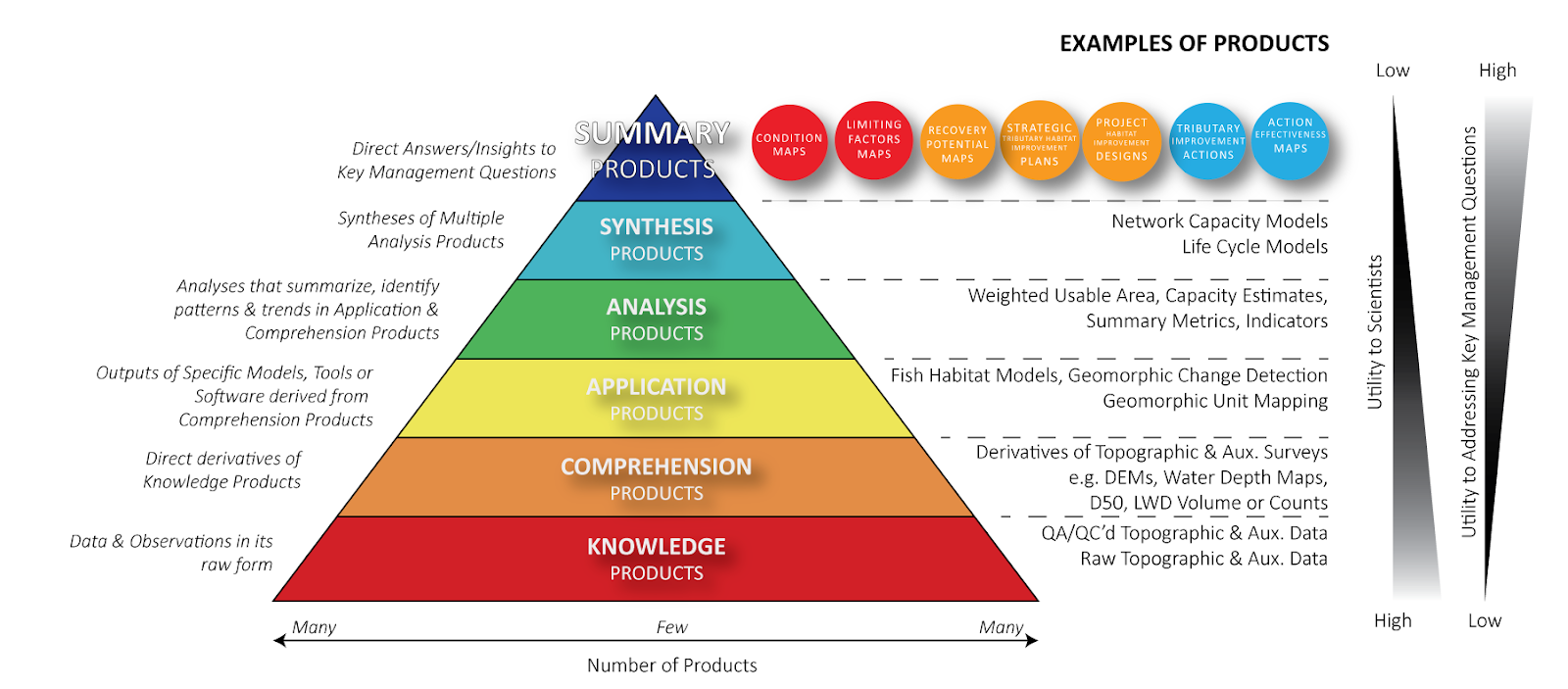
Not all datasets are created equal, nor have all received the same amount of attention, curation, validating, curation and or story telling. Drawing from and adapting Bloom’s Taxonomy of Educational Objectives, we define dataset grade in terms of a similar hierarchy of dataset curation (instead of skills and abilities) with six levels:
- Knowledge-Rank - A dataset representing raw data and observations.
- Comprehension-Rank - A dataset that is a derivative product from raw data or observation (e.g. a surface interpolated from raw sample points)
- Application-Rank - A dataset that represents the typical outputs generated in one realization from a tool or model.
- Analysis-Rank - A dataset that represents an an analysis, summary or interpretation from an application-rank dataset.
- Synthesis-Rank - A dataset that involves the pulling together of multiple analysis-rank datasets to describe a larger problem.
- Evaluation-Rank - A broader summary dataset that provides direct answers or insights into key scientific knowledge gaps or key management questions (e.g. what is published in a peer-reviewed paper as an “original contribution” or used as a basis for decision making)
In general, the higher tiered datasets represent what is filtered out through scientific inquiry from more basic and prolific datasets and observations into a higher form of knowledge. Higher-tiered datasets have more utility to managers to inform decision making, but scientists often at least want the transparency of knowing what datasets went into informing that synthesis or evaluation. Riverscapes Projects impose this transparency of what evidence every dataset originated from and allow iterative inquiry and exploration.
Idea from CHaMP
The idea to use Bloom’s Taxonomy of Educational Objectives to communicate the rank or type of curation a dataset had received grew out of a need to communicate what utility the many different datasets we were producing in the CHaMP had. The figure below shows how we referred to datasets as “products” and uses specific examples of RC-tools and models to illustrate the ideas:
Dataset Status Tags
We use three optional status tags:
- Overall Status,
- QA/QC Review, and
- Data Generation
to track the development of a dataset. However, it is the Overall Status of a dataset that is most important for tracking its progression within a Riverscape Warehouse.
| Status Tags | Overall Status | QA/QC Review | Data Generation |
|---|---|---|---|
| None | None | ||
| Exploratory | Automated Testing | End-User | |
| Provisional | Manual Testing | Manual | |
| Final | Expert Calibrated | Automated-Local | |
| Promoted | Validated | Automated-Cloud |
Overall Status
Where in the dataset life cycle the dataset exists. The four status choices represent a progression.
- Exploratory - Preliminary datasets produced by an analyst to explore how well a particular analysis works, or to what extent a dataset gives insights into specific questions (e.g., an individual model run used for a talk). This is as far as the vast majority of analyses get.
- Provisional - A dataset that has undergone some degree of automated or manual QA/QC testing.
- Final - A dataset that has been validated and is trusted for inclusion in the riverscape warehouse. Upon elevation to a finalized status a dataset is available for use by team members and authorized partners. At this point the dataset has a DOI assigned so a static version is available for later reference.
- Promoted - A dataset promoted from a finalized riverscape warehouse output to ready for external consumption. The degree of documentation and vetting is generally higher than finalized outputs. Examples may include any datasets used in the preparation of a basin or restoration plan or peer-reviewed paper.
QA/QC Review
The degree of quality assurance and quality control checks that a dataset has been subjected to. The choices are not a progression per se, and a dataset may undergo just one or all four of these states.
- Automated Testing - All tool-generated outputs undergo some degree of quality assurance and quality control checking to flag outliers and mistakes. When a dataset has received QA/QC evaluation in an automated, centralized, production mode (e.g., GCD results checked for outliers) it is automatically queued for manual editing, checking and fixing.
- Manual Testing - A manual, expert evaluation of a dataset and its reporting.
- Expert Calibrated - An optional step of modifying model outputs by model iteration or analysis to produce new output based on expert modification of inputs and/or parameters to more realistic values.
- Validated- A dataset can be considered validated after it has undergone some form of testing and the relative quality of that dataset has been assessed and reported. If the inputs and/or parameters have been calibrated or modified with expert insights and the dataset generation has been iterative, the reporting includes how dataset quality has changed with that calibration process.
Data Generation
How the data datasets were generated
- Automated Local- Generated via batch processing using local tools and/or workbench.
- Automated Cloud - Generated via cloud processing engines (e.g., EC2 or Lambda)
- Manual - Generated via local tools on an individual basis.